容器安全事件排查与响应
声明
本文为笔者对实际容器安全事件的归纳,仅代表个人观点。
引子
定位初始入侵位置
首先要确认入侵是否发生在容器内,或者说只在容器内
场景:zabbix告警一个进程占用非常高,像是挖矿程序/DOS了
但是查看进程的PPID却发现是systemd,这种情况大概率是容器相关了
首先获取程序PID,然后查看对应进程的进程树是否父进程为containerd-shim
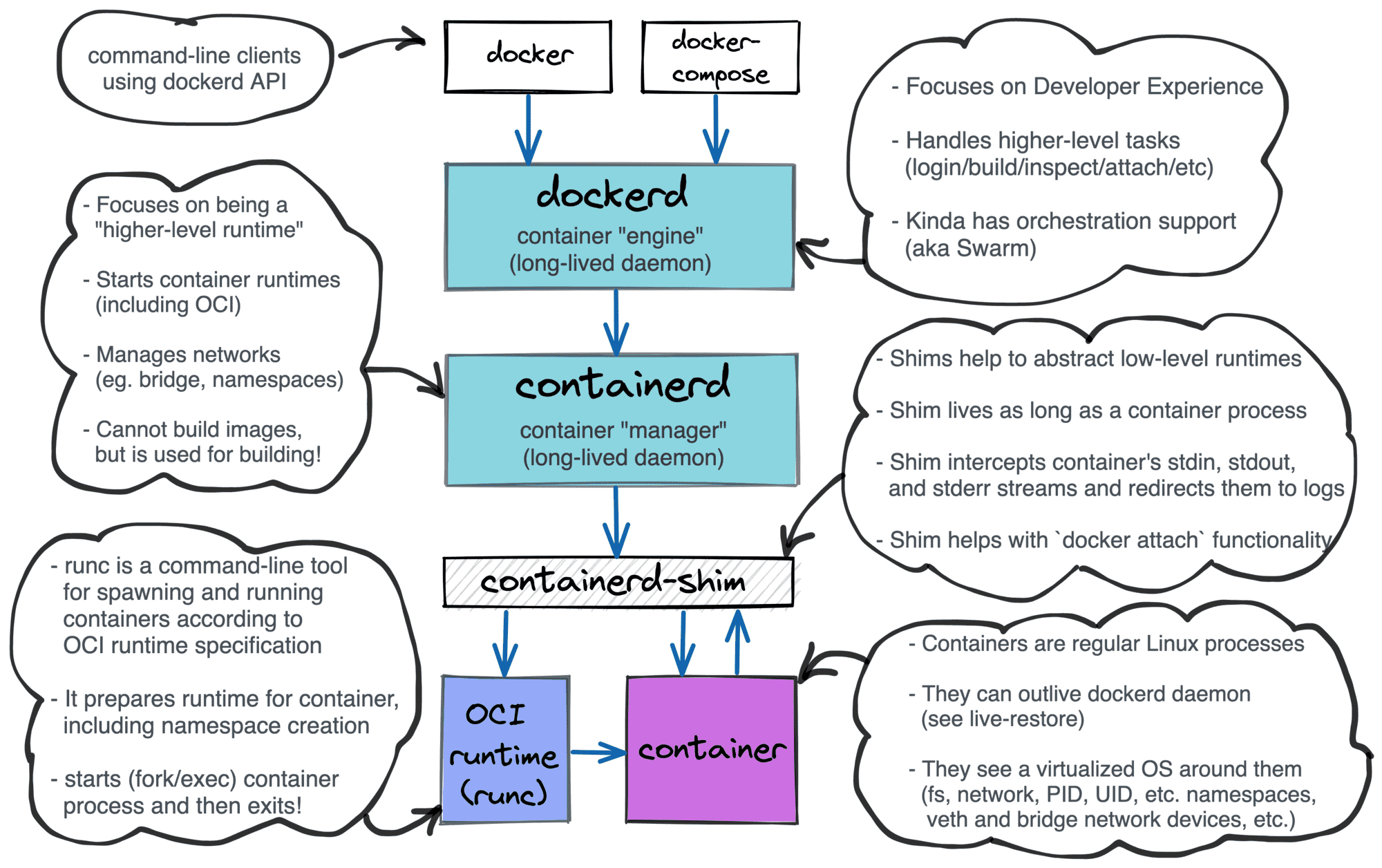
上图比较清晰的介绍了各项之间的逻辑关系,不同docker版本有些区别,具体视情况决定。
以docker为例,可以通过如下方式确认宿主机内的docker进程及对应的容器名
1 | for i in $(docker container ls --format "{{.ID}}"); do docker inspect -f '{{.State.Pid}} {{.Name}}' $i; done |
需要提醒的是,在生产环境可能有些输出进程号为0,这种不是真的PID为0,是此刻容器处于restarting状态。<br
了解环境基本信息
定位到对应的容器后,需要检查该容器的一些基本信息
检查容器对外开放端口,是否有根据经验即可判断的风险
1 | docker ps #当前运行的容器、创建时间、运行状态、映射的端口 |
检查宿主机docker环境,比如是否docker deamon api对外开放,还是有很多运维因为种种原因可能做出这类配置的。
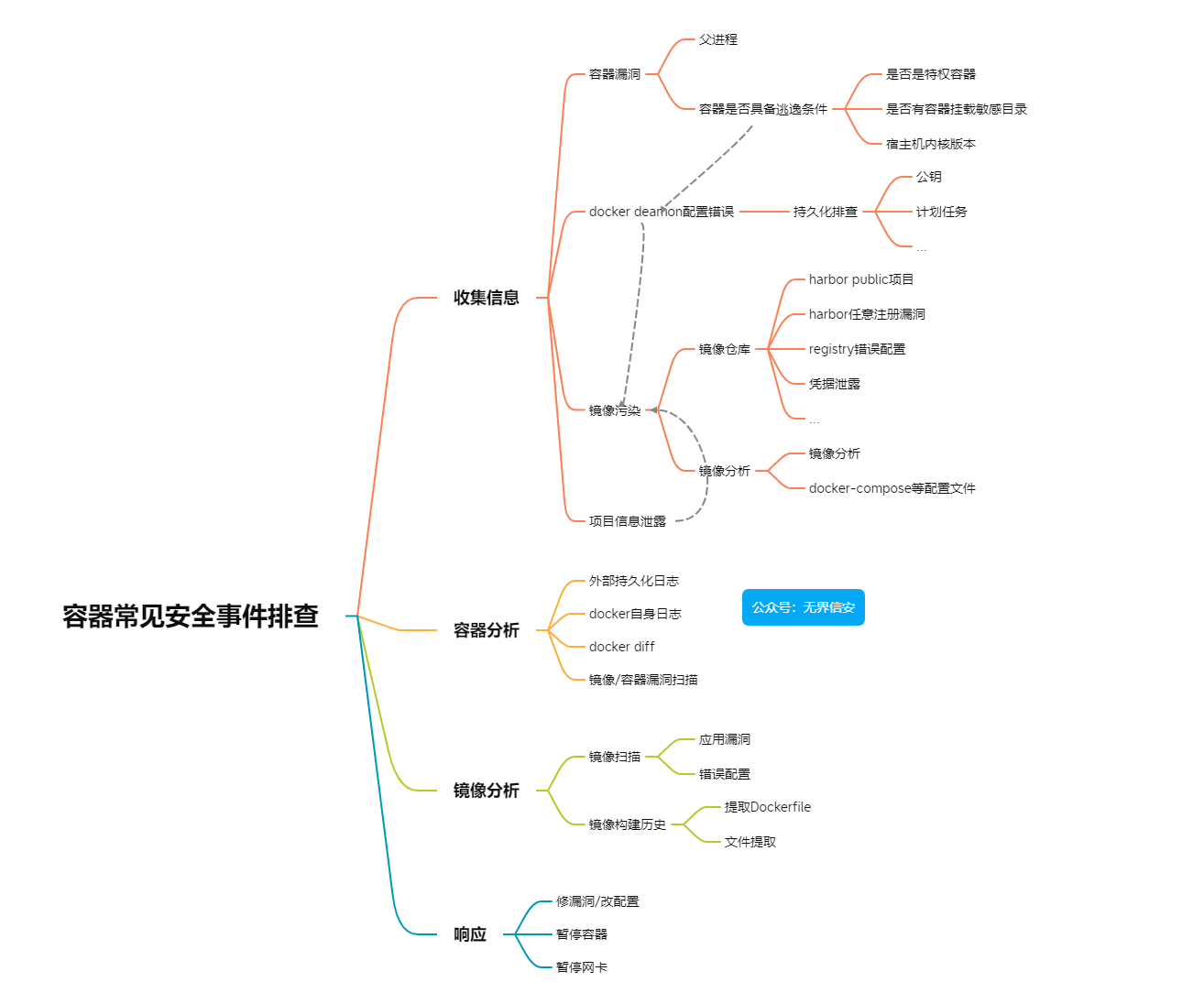
常见的容器逃逸checklist:
- 是否挂载了敏感目录
- 是否是特权容器
- 宿主机内核版本是否在常见的逃逸漏洞影响范围
- …
最后检查对应镜像的运行命令,不过多数都是docker-entrypoint.sh,最好有容器管理员侧的配合
再次确认容器在宿主机的PID
1 | docker inspect -f '{{.State.Pid}}' <容器ID> |
最后是确定当前节点使用的镜像仓库,如果使用公网仓库则需要排查是否存在被恶意拉取可能性,关于这点将在后面章节继续。
容器分析
保存容器现场
如果需要进行取证就应该先暂停处置等工作,第一步是确保现场的完整性。
1 | docker commmit <容器ID> |
因为一般跑容器的宿主机都是大内存机器,所以保存机器内存快照其实并不怎么方便。
场景:这里以redis容器空口令导致redis被写入私钥为例
环境搭建:使用vulhub环境模拟
使用redis-cli连接空口令的redis,并在tmp目录写入名为hack的文件
1 | config set dir /tmp |
容器的变更
入侵者在入侵容器后,做了什么变更,这个是比较关键的信息
1 | docker diff <容器ID> |
1 | C /tmp |
类型解释如下
| A | 添加了文件或目录 |
|---|---|
| D | 文件或目录被删除 |
| C | 文件或目录已更改 |
查看文件时间(常见的容器基础镜像都不带ll命令)
1 | docker exec -i <容器ID> ls /tmp -al |
不过生产环境噪音肯定非常大,需要一定安全知识、其他信息进行过滤
深入容器基本信息
1 | docker info #docker引擎的相关信息 |
## 容器日志分析 docker logs 所收集的日志是只包含标准输出(STDOUT)与标准错误输出(STDERR),所以粒度可能是不够的。而且容器一旦重启,docker log便会丢失。
许多知名项目在移植到docker时,也考虑到了这点,以nginx的Dockerfile为例,就是直接将access.log和error.log 软链接到stdout和stderr。
1 | ln -sf /dev/stdout /var/log/nginx/access.log |
2017年,Matt Stine在接受InfoQ采访时将Observability(可观测性)归纳为云原生的特征。在目前的CNCF中,可观测性体系的产品主要分为Monitoring监控、Logging日志 、Tracing调用链。
因此如果有外部日志服务器,那么直接到日志服务器进行检索即可,可能有更多的数据源、更专业的检索工具,可以更好的分析安全事件。本文主要讨论关于没有持久化日志的情况
继续分析上面的场景
1 | docker logs <容器ID> |
1 | 1:C 06 Mar 02:24:04.043 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo |
可以看到在06 Mar 02:24:33保存了一个DB
结合容器变更信息中,tmp目录下的文件时间,可以判断出该容器是在06 Mar 02:24被入侵,但是这个时间不完全对,因为容器的时区没有设置,date命令可以看到使用的是UTC时区
1 | docker exec -i <容器ID> date |
因为容器启动时未配置时区,默认会使用UTC。
因为是UTC时区,所以就需要将时间+8小时即Mar 6 10:30:08
其他安全设备日志
这点不多谈,容器技术在设计时考虑了很多安全性,但是基础的安全建设、设备还是需要的。
需要注意的是厂商有无容器安全案例?对于K8S等环境,POD、Node间东西向的流量是否能收集?
镜像分析
假如容器是因为被投毒,所以造成的失陷,可以通过以下方式排查。当然,如果发生了项目文件泄露也可以分析镜像排查,比如是否有.git等。
首选确定是否使用了docker-compose构建?如果使用,docker-compose.yml文件内容是哪些?
直接使用docker inspect ,就可以看到docker-compose的路径
1 | docker inspect <容器ID> | grep com.docker.compose |
镜像仓库
首先确定容器使用的镜像:是否使用了镜像仓库,除了直接问机器管理员还可以自己摸索(这点在攻击者角度也是一样的),直接通过docker info 命令查看即可。
不过,同样需要关注的是镜像仓库的凭据。和其他Linux软件一样,secret一般都在用户的环境变量,如$HOME/.docker/config.json,甚至openshift都可以通过该文件创建secret(也可以自定义的,参数是–config,且优先级更高)
1 | oc create secret generic dockerhub \ |
回归主线,查看以下json文件
1 | cat /root/.docker/config.json |
192.168.xxxx.xxx:8888即是仓库对应的IP:Port
1 | { |
这里auth的value就是用户名:密码,可以直接base64解码
1 | echo "YWRtaW46SGFyYm9yMTIzNDU=" | base64 -d |
除了其他机器失陷,导致镜像仓库凭据泄露,进而导致镜像被恶意拉取。当然也可能是harbor项目配置不当,比如配置成了public项目、registry错误配置或利用了harbor漏洞…
镜像扫描
新版本的docker已经和synk合作提供镜像扫描服务,当然也可以使用一些开源的镜像扫描工具比如
Trivy、Clair,或者是镜像仓库扫描器,比如新版本harbor就是默认集成了,其他的商业容器安全平台一般也有Adapter集成harbor用于扫描。
在扫描过程中可以发现一些应用漏洞(需要排除大量误报)+配置错误
镜像分析
在确保基础镜像的安全性后,分析镜像主要有两点:提取出镜像的构建过程和镜像构建过程中引用的文件
场景模拟:dockerhub上的一个挖矿镜像
1 | docker pull hsww/xmrig-centos7:v6.12.2 |
镜像的构建过程
使用docker history
1 | docker history --no-trunc hsww/xmrig-centos7:v6.12.2 |
效果如下,其实有点难理解,但是优点是有时间等信息
1 | IMAGE CREATED CREATED BY SIZE COMMENT |
使用dfimage工具
1 | alias dfimage="docker run -v /var/run/docker.sock:/var/run/docker.sock --rm alpine/dfimage" |
提取出的信息如下
1 | LABEL org.label-schema.schema-version=1.0 org.label-schema.name=CentOS Base Image org.label-schema.vendor=CentOS org.label-schema.license=GPLv2 org.label-schema.build-date=20201113 org.opencontainers.image.title=CentOS Base Image org.opencontainers.image.vendor=CentOS org.opencontainers.image.licenses=GPL-2.0-only org.opencontainers.image.created=2020-11-13 00:00:00+00:00 |
然后把/usr/bin/xmrig文件复制出来分析即可
1 | /usr/bin/xmrig |
因为我这里使用的是默认的overlay2驱动,可以通过docker info查看当前使用的docker 存储驱动。
最下层是lower层,是只读/镜像层
upper是容器的读写层,采用了CoW(写时复制)机制,只有对文件进行修改才会将文件拷贝到upper层,之后所有的修改操作都会对upper层的副本进行修改
upper并列还有workdir层,它的作用是充当一个中间层的作用,每当对upper层里面的副本进行修改时,会先当到workdir,然后再从workdir移动upper层
最上层是mergedir,是一个统一图层,从mergedir可以看到lower,upper,workdir中所有数据的整合,整个容器展现出来的就是mergedir层.
1 | tree -l |
构建引用的文件
这里使用dockerhub上的docker72590/apache:latest进行分析
1 | dfimage -sV=1.36 docker72590/apache:latest |
解析出的Dockerfile文件为
1 | CMD ["/bin/sh"] |
可以看到其中的关键是/home/.system文件
1 | docker inspect --format='{{.GraphDriver.Data.UpperDir}}' docker72590/apache:latest |
但是目录下没有,可能在基础镜像时已经包含了这个内容,所以得看LowerDir
1 | $docker inspect --format='{{.GraphDriver.Data.LowerDir}}' docker72590/apache:latest |
所以在这里无法显示,也可以通过dive查看镜像构建过程引用的文件
1 | docker pull wagoodman/dive #拉取dive镜像 |
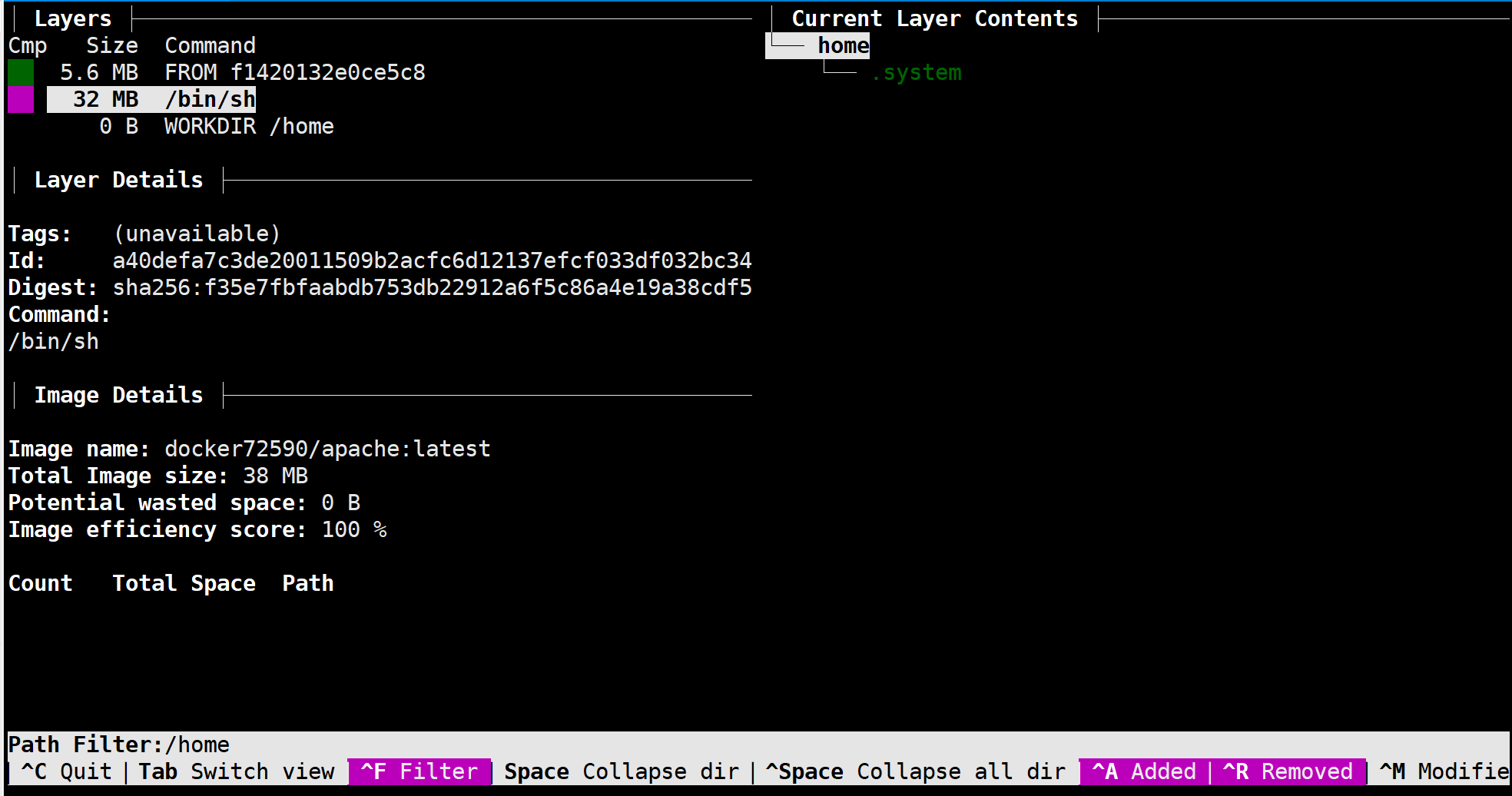
注意这里的层ID
提取镜像
1 | docker save docker72590/apache:latest -o apache.bin |
使用binwalk进行提取,其实也可以直接解压,这里我直接解压
1 | docker save docker72590/apache:latest -o apache.tar |
根据dive的信息,直接看对应的一层,找到.system,有个经验技巧就是镜像第一层会在最上面
1 | $ls a40defa7c3de20011509b2acfc6d12137efcf033df032bc34c67f04582c88a53/home -alh |
因为启动方式是sh启动,所以可以查看文件内容
1 | /bin/bash |
这里就不继续分析了
处置手段
处置第一步应该是下线相关应用/修复应用风险,而不是这些措施,不过有时候有用。
比如K8S的Cluster Autoscaler和Horizontal Pod Autoscaler等功能,假如频繁性的在一个node上阻断操作,master可能判定该node异常,因此将pod调度到其他节点,这种情况甚至可能对于攻击者毫无感知,同样的exp打过来效果可能都是一样的。
但是对于防御者来说,大大增加了处置成本,即不停的在不同node进行处置,而且需要K8S管理员频繁配合,确定POD调度的node。
下面提到的方式主要是短时止血的思路,需要结合应用部署实施的实际情况决定。
暂停容器
1 | docker pause <容器ID> |
删除容器,除非迫不得已
1 | docker rm -f <容器ID> |
小结